publications
2025
-
 A Recipe for Generating 3D Worlds From a Single ImageKatja Schwarz, Denis Rozumny, Samuel Rota Bulo, and 2 more authorsIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2025
A Recipe for Generating 3D Worlds From a Single ImageKatja Schwarz, Denis Rozumny, Samuel Rota Bulo, and 2 more authorsIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2025We introduce a recipe for generating immersive 3D worlds from a single image by framing the task as an in-context learning problem for 2D inpainting models. This approach requires minimal training and uses existing generative models. Our process involves two steps: generating coherent panoramas using a pre-trained diffusion model and lifting these into 3D with a metric depth estimator. We then fill unobserved regions by conditioning the inpainting model on rendered point clouds, requiring minimal fine-tuning. Tested on both synthetic and real images, our method produces high-quality 3D environments suitable for VR display. By explicitly modeling the 3D structure of the generated environment from the start, our approach consistently outperforms state-of-the-art, video synthesis-based methods along multiple quantitative image quality metrics.
-
 FlowR: Flowing from Sparse to Dense 3D ReconstructionsTobias Fischer, Samuel Rota Bulò, Yung-Hsu Yang, and 7 more authorsIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2025
FlowR: Flowing from Sparse to Dense 3D ReconstructionsTobias Fischer, Samuel Rota Bulò, Yung-Hsu Yang, and 7 more authorsIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 20253D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of applications like Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These models typically rely on a noise-to-data generative process conditioned only on a handful of reference input views, leading to hallucinations, inconsistent generation results, and subsequent reconstruction artifacts. Instead, we propose a multi-view, flow matching model that learns a flow to directly connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with consistent, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
-
 Generative Gaussian Splatting: Generating 3D Scenes with Video Diffusion PriorsKatja Schwarz, Norman Müller, and Peter KontschiederIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2025
Generative Gaussian Splatting: Generating 3D Scenes with Video Diffusion PriorsKatja Schwarz, Norman Müller, and Peter KontschiederIn Proc. of the IEEE International Conf. on Computer Vision (ICCV), 2025Synthesizing consistent and photorealistic 3D scenes is an open problem in computer vision. Video diffusion models generate impressive videos but cannot directly synthesize 3D representations, i.e, lack 3D consistency in the generated sequences. In addition, directly training generative 3D models is challenging due to a lack of 3D training data at scale. In this work, we present Generative Gaussian Splatting (GGS) - a novel approach that integrates a 3D representation with a pre-trained latent video diffusion model. Specifically, our model synthesizes a feature field parameterized via 3D Gaussian primitives. The feature field is then either rendered to feature maps and decoded into multi-view images, or directly upsampled into a 3D radiance field. We evaluate our approach on two common benchmark datasets for scene synthesis, RealEstate10K and ScanNet++, and find that our proposed GGS model significantly improves both the 3D consistency of the generated multi-view images, and the quality of the generated 3D scenes over all relevant baselines. Compared to a similar model without 3D representation, GGS improves FID on the generated 3D scenes by 20% on both RealEstate10K and ScanNet++.
-
 Volumetric Surfaces: Representing Fuzzy Geometries with Layered MeshesStefano Esposito, Anpei Chen, Christian Reiser, and 7 more authorsIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025
Volumetric Surfaces: Representing Fuzzy Geometries with Layered MeshesStefano Esposito, Anpei Chen, Christian Reiser, and 7 more authorsIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2025High-quality real-time view synthesis methods are based on volume rendering, splatting, or surface rendering. While surface-based methods generally are the fastest, they cannot faithfully model fuzzy geometry like hair. In turn, alpha-blending techniques excel at representing fuzzy materials but require an unbounded number of samples per ray (P1). Further overheads are induced by empty space skipping in volume rendering (P2) and sorting input primitives in splatting (P3). We present a novel representation for real-time view synthesis where the (P1) number of sampling locations is small and bounded, (P2) sampling locations are efficiently found via rasterization, and (P3) rendering is sorting-free. We achieve this by representing objects as semi-transparent multi-layer meshes, rendered in fixed order. First, we model surface layers as SDF shells with optimal spacing learned during training. Then, we bake them as meshes and fit UV textures. Unlike single-surface methods, our multi-layer representation effectively models fuzzy objects. In contrast to volume-based and splatting-based methods, our approach enables real-time rendering on low-cost smartphones.
2024
-
 MultiDiff: Consistent Novel View Synthesis from a Single ImageNorman Müller, Katja Schwarz, Barbara Rössle, and 4 more authorsIn CVPR, 2024
MultiDiff: Consistent Novel View Synthesis from a Single ImageNorman Müller, Katja Schwarz, Barbara Rössle, and 4 more authorsIn CVPR, 2024We introduce MultiDiff a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature as there exist multiple plausible explanations for unobserved areas. To address this issue we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results – even for long-term scene generation with large camera movements while reducing inference time by an order of magnitude. For additional consistency and image quality improvements we introduce a novel structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging real-world datasets RealEstate10K and ScanNet. Finally our model naturally supports multi-view consistent editing without the need for further tuning.
-
 WildFusion: Learning 3D-Aware Latent Diffusion Models in View SpaceKatja Schwarz, Seung Wook Kim, Jun Gao, and 3 more authorsIn International Conference on Learning Representations, 2024
WildFusion: Learning 3D-Aware Latent Diffusion Models in View SpaceKatja Schwarz, Seung Wook Kim, Jun Gao, and 3 more authorsIn International Conference on Learning Representations, 2024Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images’ underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data.
2023
-
 NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion ModelsSeung Wook Kim, Bradley Brown, Kangxue Yin, and 6 more authorsIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2023
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion ModelsSeung Wook Kim, Bradley Brown, Kangxue Yin, and 6 more authorsIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2023Automatically generating high-quality real world 3D scenes is of enormous interest for applications such as virtual reality and robotics simulation. Towards this goal, we introduce NeuralField-LDM, a generative model capable of synthesizing complex 3D environments. We leverage Latent Diffusion Models that have been successfully utilized for efficient high-quality 2D content creation. We first train a scene auto-encoder to express a set of image and pose pairs as a neural field, represented as density and feature voxel grids that can be projected to produce novel views of the scene. To further compress this representation, we train a latent-autoencoder that maps the voxel grids to a set of latent representations. A hierarchical diffusion model is then fit to the latents to complete the scene generation pipeline. We achieve a substantial improvement over existing state-of-the-art scene generation models. Additionally, we show how NeuralField-LDM can be used for a variety of 3D content creation applications, including conditional scene generation, scene inpainting and scene style manipulation.
2022
-
 VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel GridsKatja Schwarz, Axel Sauer, Michael Niemeyer, and 2 more authorsIn Advances in Neural Information Processing Systems (NeurIPS), 2022
VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel GridsKatja Schwarz, Axel Sauer, Michael Niemeyer, and 2 more authorsIn Advances in Neural Information Processing Systems (NeurIPS), 2022State-of-the-art 3D-aware generative models rely on coordinate-based MLPs to parameterize 3D radiance fields. While demonstrating impressive results, querying an MLP for every sample along each ray leads to slow rendering. Therefore, existing approaches often render low-resolution feature maps and process them with an upsampling network to obtain the final image. Albeit efficient, neural rendering often entangles viewpoint and content such that changing the camera pose results in unwanted changes of geometry or appearance. Motivated by recent results in voxel-based novel view synthesis, we investigate the utility of sparse voxel grid representations for fast and 3D-consistent generative modeling in this paper. Our results demonstrate that monolithic MLPs can indeed be replaced by 3D convolutions when combining sparse voxel grids with progressive growing, free space pruning and appropriate regularization. To obtain a compact representation of the scene and allow for scaling to higher voxel resolutions, our model disentangles the foreground object (modeled in 3D) from the background (modeled in 2D). In contrast to existing approaches, our method requires only a single forward pass to generate a full 3D scene. It hence allows for efficient rendering from arbitrary viewpoints while yielding 3D consistent results with high visual fidelity.
-
 ARAH: Animatable Volume Rendering of Articulated Human SDFsShaofei Wang, Katja Schwarz, Andreas Geiger, and 1 more authorIn Proc. of the European Conf. on Computer Vision (ECCV), 2022
ARAH: Animatable Volume Rendering of Articulated Human SDFsShaofei Wang, Katja Schwarz, Andreas Geiger, and 1 more authorIn Proc. of the European Conf. on Computer Vision (ECCV), 2022Combining human body models with differentiable rendering has recently enabled animatable avatars of clothed humans from sparse sets of multi-view RGB videos. While state-of-the-art approaches achieve realistic appearance with neural radiance fields (NeRF), the inferred geometry often lacks detail due to missing geometric constraints. Further, animating avatars in out-of-distribution poses is not yet possible because the mapping from observation space to canonical space does not generalize faithfully to unseen poses. In this work, we address these shortcomings and propose a model to create animatable clothed human avatars with detailed geometry that generalize well to out-of-distribution poses. To achieve detailed geometry, we combine an articulated implicit surface representation with volume rendering. For generalization, we propose a novel joint root-finding algorithm for simultaneous ray-surface intersection search and correspondence search. Our algorithm enables efficient point sampling and accurate point canonicalization while generalizing well to unseen poses. We demonstrate that our proposed pipeline can generate clothed avatars with high-quality pose-dependent geometry and appearance from a sparse set of multi-view RGB videos. Our method achieves state-of-the-art performance on geometry and appearance reconstruction while creating animatable avatars that generalize well to out-of-distribution poses beyond the small number of training poses.
-
 StyleGAN-XL: Scaling StyleGAN to Large Diverse DatasetsAxel Sauer, Katja Schwarz, and Andreas GeigerIn ACM Trans. on Graphics, 2022
StyleGAN-XL: Scaling StyleGAN to Large Diverse DatasetsAxel Sauer, Katja Schwarz, and Andreas GeigerIn ACM Trans. on Graphics, 2022Computer graphics has experienced a recent surge of data-centric approaches for photorealistic and controllable content creation. StyleGAN in particular sets new standards for generative modeling regarding image quality and controllability. However, StyleGAN’s performance severely degrades on large unstructured datasets such as ImageNet. StyleGAN was designed for controllability; hence, prior works suspect its restrictive design to be unsuitable for diverse datasets. In contrast, we find the main limiting factor to be the current training strategy. Following the recently introduced Projected GAN paradigm, we leverage powerful neural network priors and a progressive growing strategy to successfully train the latest StyleGAN3 generator on ImageNet. Our final model, StyleGAN-XL, sets a new state-of-the-art on large-scale image synthesis and is the first to generate images at a resolution of 1024x1024 at such a dataset scale. We demonstrate that this model can invert and edit images beyond the narrow domain of portraits or specific object classes.
2021
-
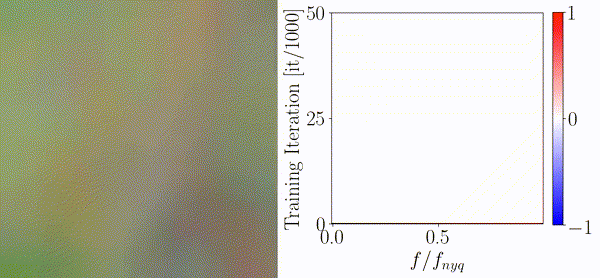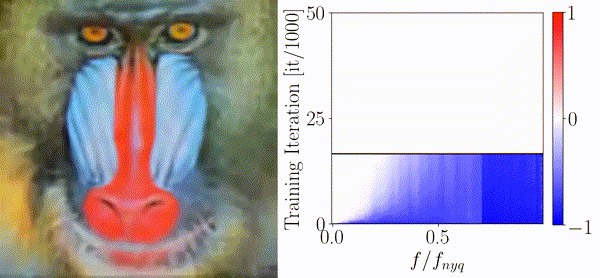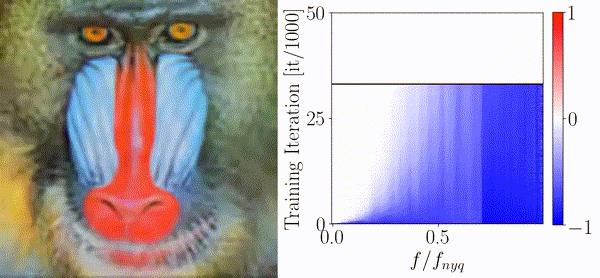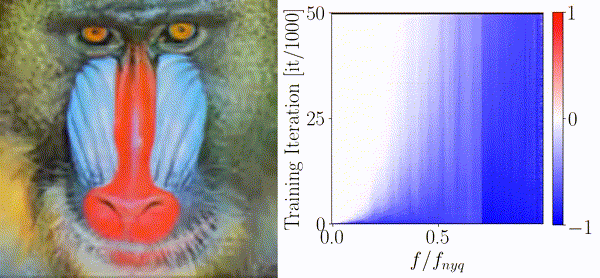 On the Frequency Bias of Generative ModelsKatja Schwarz, Yiyi Liao, and Andreas GeigerIn Advances in Neural Information Processing Systems (NeurIPS), 2021
On the Frequency Bias of Generative ModelsKatja Schwarz, Yiyi Liao, and Andreas GeigerIn Advances in Neural Information Processing Systems (NeurIPS), 2021The key objective of Generative Adversarial Networks (GANs) is to generate new data with the same statistics as the provided training data. However, multiple recent works show that state-of-the-art architectures yet struggle to achieve this goal. In particular, they report an elevated amount of high frequencies in the spectral statistics which makes it straightforward to distinguish real and generated images. Explanations for this phenomenon are controversial: While most works attribute the artifacts to the generator, other works point to the discriminator. We take a sober look at those explanations and provide insights on what makes proposed measures against high-frequency artifacts effective. To achieve this, we first independently assess the architectures of both the generator and discriminator and investigate if they exhibit a frequency bias that makes learning the distribution of high-frequency content particularly problematic. Based on these experiments, we make the following four observations: 1) Different upsampling operations bias the generator towards different spectral properties. 2) Checkerboard artifacts introduced by upsampling cannot explain the spectral discrepancies alone as the generator is able to compensate for these artifacts. 3) The discriminator does not struggle with detecting high frequencies per se but rather struggles with frequencies of low magnitude. 4) The downsampling operations in the discriminator can impair the quality of the training signal it provides. In light of these findings, we analyze proposed measures against high-frequency artifacts in state-of-the-art GAN training but find that none of the existing approaches can fully resolve spectral artifacts yet. Our results suggest that there is great potential in improving the discriminator and that this could be key to match the distribution of the training data more closely.
2020
-
 GRAF: Generative Radiance Fields for 3D-Aware Image SynthesisKatja Schwarz, Yiyi Liao, Michael Niemeyer, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS), 2020
GRAF: Generative Radiance Fields for 3D-Aware Image SynthesisKatja Schwarz, Yiyi Liao, Michael Niemeyer, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS), 2020While 2D generative adversarial networks have enabled high-resolution image synthesis, they largely lack an understanding of the 3D world and the image formation process. Thus, they do not provide precise control over camera viewpoint or object pose. To address this problem, several recent approaches leverage intermediate voxel-based representations in combination with differentiable rendering. However, existing methods either produce low image resolution or fall short in disentangling camera and scene properties, e.g., the object identity may vary with the viewpoint. In this paper, we propose a generative model for radiance fields which have recently proven successful for novel view synthesis of a single scene. In contrast to voxel-based representations, radiance fields are not confined to a coarse discretization of the 3D space, yet allow for disentangling camera and scene properties while degrading gracefully in the presence of reconstruction ambiguity. By introducing a multi-scale patch-based discriminator, we demonstrate synthesis of high-resolution images while training our model from unposed 2D images alone. We systematically analyze our approach on several challenging synthetic and real-world datasets. Our experiments reveal that radiance fields are a powerful representation for generative image synthesis, leading to 3D consistent models that render with high fidelity.
-
 Towards Unsupervised Learning of Generative Models for 3D Controllable Image SynthesisYiyi Liao, Katja Schwarz, Lars Mescheder, and 1 more authorIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020
Towards Unsupervised Learning of Generative Models for 3D Controllable Image SynthesisYiyi Liao, Katja Schwarz, Lars Mescheder, and 1 more authorIn Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020In recent years, Generative Adversarial Networks have achieved impressive results in photorealistic image synthesis. This progress nurtures hopes that one day the classical rendering pipeline can be replaced by efficient models that are learned directly from images. However, current image synthesis models operate in the 2D domain where disentangling 3D properties such as camera viewpoint or object pose is challenging. Furthermore, they lack an interpretable and controllable representation. Our key hypothesis is that the image generation process should be modeled in 3D space as the physical world surrounding us is intrinsically three-dimensional. We define the new task of 3D controllable image synthesis and propose an approach for solving it by reasoning both in 3D space and in the 2D image domain. We demonstrate that our model is able to disentangle latent 3D factors of simple multi-object scenes in an unsupervised fashion from raw images. Compared to pure 2D baselines, it allows for synthesizing scenes that are consistent wrt. changes in viewpoint or object pose. We further evaluate various 3D representations in terms of their usefulness for this challenging task.